ЎЎЎЎҪьИХ,өЪ11ҪмICAART(№ъјКЦЗДЬМеУлИЛ№ӨЦЗДЬ»бТй)ФЪҪЭҝЛКЧ¶јІјАӯёсХЩҝӘ,ОӘЖЪИэМмЎЈ
ЎЎЎЎЧФ2009ДкҫЩ°мөЪТ»ҪмТФАҙ,ICAARTГҝДк¶јҫЫјҜБЛҙуЕъ¶ФЦЗДЬМеәНИЛ№ӨЦЗДЬБмУтёРРЛИӨөДҝЖС§јТЎўСРҫҝФұЎў№ӨіМКҰЎўәНПа№ШҙУТөИЛФұЎЈ
ЎЎЎЎ»бТй·ЦБҪёц·ҪПт:ЧЁЧўУЪЦЗДЬМеЎў¶аЦЗДЬМеПөНіәНИнјюЖҪМЁЎўТФј°·ЦІјКҪИЛ№ӨЦЗДЬ;ТФј°ІаЦШУЪИЛ№ӨЦЗДЬЎўЦӘК¶ұнКҫЎў№ж»®ЎўС§П°Ўўөч¶ИЎўёРЦӘ·ҙУҰРФИЛ№ӨЦЗДЬПөНіЎўҪш»ҜјЖЛгТФј°УлЦЗДЬПөНіәНјЖЛгЦЗДЬПа№ШөДЖдЛыЦчМвЎЈ
ЎЎЎЎҪсДкөДЦчМвСЭҪІСыЗлөҪБЛЛДО»АҙЧФИ«ЗтІ»Н¬өШЗшёЯөИС§ё®өДС§КхИЁНю,СЭҪІЦчМвәӯёЗИЛ№ӨЦЗДЬЎў·ВХжјјКхЎўҪш»ҜТХКхЎўКЦРҙК¶ұрЎўјЖЛгҝЙіЦРшРФөИИИГЕТйМвЎЈұҫОДМфСЎБЛЖдЦРИэО»СЭҪІИЛ,¶ФЖдСЭҪІДЪИЭБЛҪшРРёЯ¶ИМбБ¶әНёЕАЁЎЈ
ЎЎЎЎҙЛНв,ҪсДкICAARTҙу»бЧојСВЫОДУЙАҙЧФГА№ъBShalem ResearchөДСРҫҝФұAvi Bleiweiss»сөГ,ЛыМбіцБЛТ»ЦЦ»щУЪLSTM(іӨ¶МЖЪјЗТдНшВз)өДЙсҫӯНшВзДЈРН,НЁ№эЗЁТЖС§П°өД·Ҫ·Ё,ҙУПа¶ФҪПҙуөДКэҫЭјҜЙП»сөГФӨСөБ·ДЈРНИ»әуФЪМШ¶ЁПЎКиКэҫЭјҜЙПҪшРРУЕ»Ҝ,МбёЯ¶ФНшВзОкИиРФЖАВЫҪшРР·ЦАаөДДҝұкРФДЬЎЈұҫОДҪ«¶ФВЫОДДЪИЭҪшРРјтТӘёЕКцЎЈ
ЎЎЎЎҪш»ҜТХКхУл»ъЖчС§П°
ЎЎЎЎ
ЎЎЎЎКЧПИөЗМЁСЭҪІөДКЗАҙЧФЖПМССАҝЖУўІјАӯҙуС§өДҪМКЪPenousal Machado
ЎЎЎЎMachadoІ©КҝДҝЗ°БмөјҝЖУўІјАӯҙуС§өДИПЦӘәНГҪМеПөНіЎЈЛыөДСРҫҝРЛИӨ°ьАЁҪш»ҜјЖЛгЎўјЖЛгҙҙФмБҰәНҪш»Ҝ»ъЖчС§П°ЎЈіэБЛХвР©БмУтөДЦЪ¶аҝЖС§ВЫОДНв,Лы»№»сөГ№э°ьАЁЕ·ЦЮҪш»ҜјЖЛгҪЬіц№ұПЧҪұEvoStarҪұЎўТФј°ЖПМССАИЛ№ӨЦЗДЬРӯ»бКЪУиөДИЛ№ӨЦЗДЬЧҝФҪҪұәНУЕРгҪұЎЈ ЛыөДЧчЖ·ФшФЪЖПМССА№ъјТөұҙъТХКхІ©Оп№ЭәНЕҰФјПЦҙъТХКхІ©Оп№Э(MoMA)ЦРХ№іцЎЈ
ЎЎЎЎMachadoІ©КҝөДСЭҪІЦчМвКЗЎ°Ҫш»ҜТХКх(Evolving Art)ЎұЎЈҪьДкАҙ,Ҫш»ҜјЖЛгјјКхУҰУГУЪТХКхөД¶аёцБмУтЎЈMachadoІ©КҝөДСЭҪІЦШөгКЗИзәОК№УГЛьГЗАҙҙҙҪЁІ»Н¬АаРНөДҙҙЧчЎўБмУтөДЦчТӘМфХҪЎўТФј°№эИҘөДҝӘ·ўИзәОУлөұЗ°өД·Ҫ·ЁЎўЗчКЖәНМфХҪПа№ШБӘЎЈ
ЎЎЎЎҪш»ҜТХКхөДұнҙпәНЖА№А
ЎЎЎЎҪш»ҜТХКхФЪ№ъДЪ»тРнКЗТ»ёцД°ЙъөДёЕДо,ЙхЦБЛьөДіКПЦ·ҪКҪҪвКНЖрАҙ¶јІ»М«ИЭТЧЎЈ
ЎЎЎЎҪш»ҜТХКхКЗЙъіЙТХКх(generative art)өДТ»ёц·ЦЦ§,ХвТвО¶ЧЕТХКхјТұҫЙнКЗІ»ІОУлТХКхЖ·өДЦЖЧч,¶шКЗИГТ»ёцЧФЦчПөНі(ұИИзјЖЛг»ъ)ҪшРРҙҙЧчЎЈ
ЎЎЎЎјтөҘ¶шСФ,Ҫш»ҜТХКхНЁ№эҪш»ҜјЖЛгАҙ»жНј,ФЪІ»¶ПөШөьҙъәу,ЧоЦХ»сөГТ»јюТХКхЧчЖ·ЎЈҫЩТ»ёцАэЧУ,Ж©ИзДгҝҙөҪТ»Ц»ГЁөДНјЖ¬әу,ПлТӘФЪГЁЙнЙПјУИлТ»Р©тщтрөДФӘЛШ,іМРт»бёщҫЭДгөДСЎФсСЭұдіцТ»ЧйРВөДЙъОп,И»әуДгҝЙТФјМРшСЎФс,ЦұөҪХТөҪЛыГЗПІ»¶өДЙъОпРОМ¬ЎЈХвҫНјӨ·ўіцБЛОЮПЮөДҙҙФмБҰ,ҪбәПҪш»ҜјЖЛгәНТХКхБмУт,ТХКхјТҝЙТФМҪЛчЛыГЗҙУОҙГОПл№эөДКВОп
ЎЎЎЎ»ШөҪСЭҪІұҫЙн,MachadoІ©КҝКЧПИҪйЙЬБЛТ»ПВҪш»ҜТХКх30¶аДкАъК·ЙПөДТ»Р©ЦШТӘИЛОп,°ьАЁКЧҙОМбіцҪш»ҜТХКхёЕДоөДRichard DawkinsЎўKarl SimsЎўWilliam LathamЎўәНSteven RookeЎЈ
ЎЎЎЎҪш»ҜТХКхЦРУРБҪёц№ШјьОКМв:Т»КЗұнКҫ·Ҫ·Ё,¶юКЗЖА№А·Ҫ·ЁЎЈ
ЎЎЎЎКЧПИКЗұнКҫ·Ҫ·ЁЎЈMachadoІ©КҝҪйЙЬБЛҪш»ҜТХКхЦРөДТ»ёц»щұҫёЕДо:»щУЪұнҙпКҪөДҪш»ҜНјПсЎЈ1991Дк,Ҫш»ҜТХКхөДҝӘҙҙХЯKarl SimsМбіцБЛТЕҙ«ұаіМ,К№УГ»щУЪұнҙпКҪөД·Ҫ·ЁАҙКөПЦНјПсҪш»Ҝ,ПФЦшөШМбЙэБЛҪш»ҜНјПсөДёҙФУ¶ИәНЙуГАР§№ыЎЈ
ЎЎЎЎҫЩёцАэЧУ:НјПс1ҝЙТФУГA*BұнКҫ,НјПсBҝЙТФУГC*DұнКҫ,НЁ№эТЕҙ«ұаіМ,ЛыГЗҪш»ҜіцөДЧУНјПсҝЙТФКЗA*BЎўC*DЎўA*CЎўB*D,Из№ыК№УГЛж»ъДЈКҪ,ДЗГҙЛыГЗөДҝЙДЬРФ»№»бУРёь¶аЎЈ
ЎЎЎЎНЁ№эХвЦЦ·Ҫ·Ё,MachadoІ©КҝИПОӘҪш»ҜТХКхҝЙТФҪш»ҜіЙИОәОТ»ЦЦҝЙДЬРФЎЈ
ЎЎЎЎХвАпMachadoІ©КҝМбөҪБҪёцЦШТӘөДҪш»ҜТХКхУҰУГЎЈөЪТ»ёцКЗҪш»ҜТХКх№ӨҫЯNEVAR,УЙMachadoІ©КҝФЪ1997ДкҙҙҪЁ,ЛьөДУЕөгФЪУЪЛьФКРнҙжҙў№эИҘҙҙҪЁөДНјПс,ИГХвР©НјҝЙТФУГЧчРВНјПсөДЖрөгЎЈNEVARФЛРРФЪІўРРҪш»ҜЛг·ЁЙП,ХвТвО¶ЧЕУГ»§ҝЙТФН¬КұФЛРР¶аёцКөСйЎЈ
ЎЎЎЎБнТ»ёцКЗPICBREEDER,ХвКЗТ»ёц»щУЪҪш»ҜТХКхёЕДоөДРӯЧчТХКхУҰУГіМРт,ХвЦЦјјКхҝЙТФИГНјЖ¬Пс¶ҜОпТ»Сщ·ұЦіЎЈ
ЎЎЎЎЖдҙОКЗЖА№А·Ҫ·ЁЎЈИзәОИГУГ»§ҙУҪш»ҜТХКхЧчЖ·»сөГГАёР,И»әуҪ«ЖА№АіцАҙөДәГҪб№ыҪЁБўіЙПаУҰөДККУҰ¶ИәҜКэ(fitness functions)јУИлөҪҪш»Ҝ№эіМЦР,ТФКөПЦІ»Н¬өДЙуГАКУҫхР§№ыЎЈ
ЎЎЎЎMachadoІ©КҝМбөҪБЛРн¶а·Ҫ·Ё,ұИИзҙ«НіөДГАС§ёЕДо,°ьАЁ»ЖҪрұИАэЎў·ЦРОО¬КэЎўАӯ·т¶ЁВЙөИ;ёҙФУРФКЗТ»ЦЦГАС§Па№ШөДМШХч,КУҫхЙПёҙФУө«ТЧУЪҙҰАнөДНјПсНщНщУРИӨ;¶ФәЪ°ЧНјЖ¬ҝЙТФК№УГ·ЦРОәНJPEGС№Лх№АјЖНјПсёҙФУ¶И;І»Н¬өДККУҰәҜКэТІДЬәПІўФЪТ»Жр,ұИИзёҙФУ¶ИЎў¶ФұИЙ«ЎўәНСХЙ«ҪҘұдЎЈ
ЎЎЎЎҪьјёДк,MachadoІ©КҝТІҝӘ·ўБЛәНУГ»§КөПЦ»Ҙ¶ҜөДҪ»»ҘҪзГж,ИГУГ»§ҫц¶ЁЧФјәҫц¶ЁККУҰәҜКэ,Ҫш»Ҝіц·ыәПЛыГЗПІәГөДНјПсЎЈ
ЎЎЎЎ2. »ъЖчС§П°
ЎЎЎЎФЪҪш»ҜТХКхЦРјУИл»ъЖчС§П°ҝЙТФЧ·ЛЭөҪ1994Дк,өұКұөДСРҫҝФұМбТйНЁ№эК№УГИЛ№ӨЙсҫӯНшВзКөПЦЧФ¶Ҝ»ҜНјПсҪш»Ҝ№эіМЎЈХвПоСРҫҝЦчТӘКЗУГ»ъЖчС§П°өД·ҪКҪС§П°УГ»§өДЖ«әГ,ІўУҰУГХвР©ЦӘК¶АҙҪш»Ҝ»сөГГАС§ЙПБоИЛУдФГөДНјПсЎЈ
ЎЎЎЎСРҫҝұнГч,»ъЖчС§П°ИЎөГБЛТ»¶ЁөДР§№ы,әНҫщФИёЕВКөДЛж»ъ№эіМПаұИ,ИЛ№ӨЙсҫӯНшВзНЁіЈДЬЦЖЧчіцёьёҙФУөДНјПсЎЈө«УЙУЪҪш»ҜНјПсКэҫЭјҜұҫЙнөДЦКБҝәНКХјҜДС¶И,өјЦВФЪКөјКЧФ¶Ҝ»ҜөД№эіМЦРУцөҪІ»ЙЩДСМвЎЈ
ЎЎЎЎ2012Дк,MachadoІ©КҝөДТ»ПоСРҫҝИЎөГБЛБоИЛТвПлІ»өҪөДҪшХ№ЎӘҪбәП»ъЖчС§П°,Ҫш»ҜТХКхҫ№ДЬІъЙъҫЯПуНјПсЎЈСРҫҝұнГч,К№УГ»щУЪНЁУГұнҙпөДТЕҙ«ұаіМНјПсЙъіЙТэЗжәНГжІҝјмІвЖчПөНі,ПөНіДЬ№»Ҫш»ҜіцТ»Р©ҝҙЙПИҘПсКЗИЛБі»тХЯКЗГжҫЯөДНјПсЎЈ
ЎЎЎЎЛжәуөДјёДкАп,Ҫш»ҜТХКхәН»ъЖчС§П°Ц®јдөДБӘПөФҪАҙФҪ¶аЎЈЖ©Из,2016ДкөДТ»·ЭСРҫҝҫНұнГч,К№УГҪш»ҜТХКхҝЙТФЙъіЙАаЛЖИЛБіИҙОЮ·Ёұ»К¶ұріЙИЛБіөДНјПс,ХвҝЙТФ°пЦъИЛБіК¶ұрПөНіФцјУСөБ·КэҫЭ,ҪЁБўЕУҙуөДКэҫЭјҜЎЈ
ЎЎЎЎҪьјёДк,¶Фҝ№ЙъіЙНшВз(GAN)Ҫ«ЙъіЙТХКхөДЛ®ЖҪУЦМбЙэБЛТ»ҙуҪШ,ФЪ2017ДкөДТ»ЖӘВЫОДЦР,СРҫҝФұҝӘ·ўБЛТ»ёц»щУЪGANөДПөНі,ДЬ№»НЁ№э№ЫІмТХКхәНС§П°·зёсАҙҙҙЧчТХКх;НЁ№эЖ«АлС§П°·зёс,ФцјУТХКхөД»ҪРСЗұБҰ,ҙУ¶шұдөГё»УРҙҙФмБҰЎЈ
ЎЎЎЎИҘДк,КЧХЕ»щУЪGANҙҙЧчөДУН»ӯФЪјСКҝөГЕДВфЦРРДВфіцБЛ43НтГАФӘ,ҫЎ№ЬХвФЪТХКхКАҪзАпЦ»КЗёцРЎКэЧЦ,ө«№«ЦЪТАИ»ДСТФПаРЕТ»ёц»ъЖчөД»ӯЧчДЬЕДВфіцХвГҙёЯөДјЫёсЎЈ
ЎЎЎЎХвТІТэіцБЛMachadoІ©КҝФЪСЭҪІЦРөДОКМв:Ў°Хв(ИЛ№ӨЦЗДЬөД»ӯЧч)КЗТХКхВр?Ўұ
ЎЎЎЎ3. ТХКхІ»КЗТХКхҙҙЧч,¶шКЗ¶ФТХКхөДИИ°®
ЎЎЎЎMachadoІ©КҝЛжәуұЬҝӘБЛХвёцГфёРөДОКМв,МбөҪБЛБнТ»ёцОКМв:Ў°ИЛ№ӨЦЗДЬКЗТХКхјТВр?Ўұ
ЎЎЎЎЛыөДҙр°ёКЗ:ПФИ»І»КЗЎЈMachadoІ©КҝИПОӘ,ИЛ№ӨЦЗДЬІ»КЗТХКхјТөДФӯТтКЗЎ°ТХКхІ»КЗТХКхҙҙЧч,¶шКЗ¶ФТХКхөДИИ°®ЎЈЎұЎ°Из№ыДгТӘФмТ»ёцИЛ№ӨТХКхјТ,ДгКЧПИТӘҝӘ·ўТ»ёцПөНі,ФЪГж¶ФТ»·щТХКхЧчЖ·Кұ,ДЬЛөЎҜХвКЗТ»·щәГЧчЖ·ЎҜЎұЎЈИз№ыГ»УР¶ФТХКхөДПІ°®әНјшЙНДЬБҰ,ДЗГҙөҘҙҝТАҝҝДЈ·ВәНҪијшөДИЛ№ӨЦЗДЬҫНІ»ДЬұ»іЖОӘТХКхјТЎЈ
ЎЎЎЎКЦРҙК¶ұрәНЙо¶ИС§П°
ЎЎЎЎ
ЎЎЎЎЛжәуСЭҪІөДКЗАҙЧФәЙАјёсВЮДюҙуС§өДҪМКЪLambertSchomaker
ЎЎЎЎSchomakerІ©КҝКЗёсВЮДюёщҙуС§ИЛ№ӨЦЗДЬҪМКЪ,ІўөЈИОёГҙуС§ИЛ№ӨЦЗДЬСРҫҝЛщЛщіӨ,Н¬КұТІКЗIAPR(№ъјКДЈКҪК¶ұрРӯ»б)іЙФұәНIEEEёЯј¶іЙФұЎЈЛыТФДЈДвәНКЦРҙК¶ұрЎўЧЦјЈК¶ұрЎўОДөө·ЦОцЎўТФј°»ъЖчС§П°СРҫҝ¶шОЕГы,З°әуТ»№ІЧ«РҙБЛ200¶аұҫіц°жОп,ІўІОУлБЛРн¶аКЦРҙК¶ұрәНОДөө·ЦОц»бТйөДЧйЦҜ№ӨЧчЎЈ
ЎЎЎЎSchomakerІ©КҝөДСЭҪІЦчМвКЗЎ°ҙу№жДЈОКМвөДБ¬РшС§П°ЎӘ¶аҪЕұҫАъК·КЦРҙОДөөјҜөДЗйҝцЎЈЎұТФҫн»эЙсҫӯНшВз(CNN)ОӘҙъұнөДЙо¶ИС§П°јјКх,ЖдЧоРВҪшХ№ФЪРн¶аУҰУГБмУтЦРБоИЛУЎПуЙоҝМЎЈХвР©·Ҫ·ЁКЗ·сТІККУГУЪәұјыөДҪЕұҫәНКЦРҙК¶ұр?Из№ыСөБ·КэҫЭБҝСПЦШКЬПЮФхГҙ°м?Из№ыУГ»§ТӘЗуЛжЧЕКұјдөДНЖТЖІ»¶Пұд»ҜёГФхГҙ°м?
ЎЎЎЎ1. КІГҙКЗКЦРҙК¶ұр?
ЎЎЎЎ№гТеЙП,КЦРҙК¶ұрОКМв(handwriting recognition)КЗСРҫҝЛг·ЁИзәОҪ«КЦРҙІъЙъөДУРРт№мјЈЎӘ°ьАЁЧЦ·ыЎўөҘҙКЎў»тёьҙу¶ФПуЎӘЧӘ»ҜОӘјЖЛг»ъҝЙК¶ұрөД·ыәЕҙъВл»тҙъВлЧЦ·ыҙ®ЎЈ
ЎЎЎЎҫЎ№Ь»ъЖчС§П°ДЈРНТСҫӯФЪКЦРҙКэЧЦК¶ұрКэҫЭјҜMNISTЙПИЎөГ·ЗіЈҫӘИЛөДіЙјЁ,ө«КЗХыёцКЦРҙК¶ұрБмУтөДОКМв»№Ф¶Г»УРұ»ҪвҫцЎЈ
ЎЎЎЎТФКЦРҙөҘҙКК¶ұр(handwriting text recognition)ОӘАэ,ХвПоСРҫҝКЗФЪМṩҫдЧУ»т¶ОВдНјПсКұ,Лг·ЁДЬМṩНкХыөДОДұҫјЩЙиЎЈХвҫНІ»өҘөҘКЗ·ыәЕК¶ұрөД№ӨЧч,»№РиТӘУпСФНіјЖС§;КЦРҙјмЛч(handwriting retrieval)ФтКЗБнТ»ҙуМфХҪ,ХвКЗөұёш¶ЁөҘҙК»тЧЦ·ыНјПсөДКөАэКұ,Лг·ЁДЬҙУКХјҜ¶шАҙөДКЦёејҜәП,ТАХХЖҘЕд¶ИҪшРРЕЕРтЎЈ
ЎЎЎЎНјПс·ЦёоТІКЗКЦРҙК¶ұрЦРөДЦШТӘ»·ҪЪ,ФЪК¶ұрКЦРҙОДЧЦөДИООсАп,өЪТ»ІҪНщНщКЗТі·ЦёоәНРР·ЦёоЎЈК¶ұрВКИз№ыГ»УРБоИЛВъТв,Т»Іҝ·ЦФӯТтҝЙТФ№йҫМФЪ·ЦёоІ»ЧјИ·ЙПЎЈSchomakerІ©КҝМбөҪ,ФЪРиТӘОДЧЦ·ЦёоөДЗйҝцПВ»бК№УГCNNДЈРН;Из№ыІ»РиТӘ·Цёо,Фт»бІЙУГТюРОВн¶ыҝЖ·тДЈРН(HMM)»тХЯКЗLSTMЎЈ
ЎЎЎЎ2. MonkПөНі
ЎЎЎЎЧчОӘёГБмУтөДИЁНюЧЁјТ,SchomakerІ©КҝҪйЙЬБЛЛыЦчөјҝӘ·ўөДИЛ№ӨЦЗДЬПөНі ЎӘ Monk,Т»ёцҝЙҪ»»ҘСөБ·өДЛСЛчТэЗжәНУГУЪАъК·КЦёеөД·юОсПөНіЎЈ
ЎЎЎЎMonkПөНіЦчТӘУЙБҪёцІҝ·ЦЧйіЙ: УГУЪЙЁГиТіГжНјПсј°ЖдІҝ·ЦөДҙжҙўәН»щУЪНшВзЧўКНөДЙиЦГ;Т»МЧ(КЦРҙәНОДұҫ)К¶ұрЛг·ЁТФј°јмЛчәНЛСЛч·Ҫ·ЁЎЈ
ЎЎЎЎёГПоДҝУЪ2005ДкЖф¶Ҝ,ІўФЪ2009ДкҪшИлЧФЦчСөБ·ДЈКҪ,К№УГЕЕ¶УПөНіҪвҫцФ¶іМі¬ЛгЧКФҙ,ІўёщҫЭУГ»§»о¶ҜҝӘКјС§П°КЦРҙК¶ұрөДИООс,7Мм24РЎКұЧФ¶ҜҪшРРҙуІҝ·Ц№ӨЧчЎЈөұКұөДСөБ·№эіМҙУИЛ№ӨұкЧўЎўөҪДЈРНөчІОЎўФЩөҪНкіЙ¶ФДҝұкБРұнјмЛчөДјЖЛг,·ЕФЪК®ДкЗ°»№КЗІ»¶ајыөДЎЈ
ЎЎЎЎФЪМбЙэMonkРФДЬЙП,SchomakerІ©КҝІЙУГБЛҫЙҝуҫ®өзМЭФӯАнЎӘЎӘПИУГ·Ҫ·ЁAҪ«ДЈРНРФДЬМбЙэЦБЧоҙу,И»әуК№УГТ»ёцХэҪ»·Ҫ·ЁBҝЙТФФЩНщЙПМбЙэР©,И»әуФЩ»ШөҪ·Ҫ·ЁA,ТАҙОСӯ»·,ЦұөҪҙпөҪҪҘҪьПЯЎЈ
ЎЎЎЎMonkөДИнУІјюЕдЦГИзПВ:
ЎЎЎЎЈҝ ёЯРФДЬLinux e-Science»·ҫі:900TB/28әЛ/126GB;
ЎЎЎЎЈҝ ¶аМејЬ№№;
ЎЎЎЎЈҝ УГ»§ұкјЗКВјюҙҘ·ўЧЁУГјЖЛг¶УБР;
ЎЎЎЎЈҝ ФЪ¶аёцЎўФ¶іМөДҪЪөгЙПјЖЛг,ұИИз(IBM Zurich);
ЎЎЎЎЈҝ ·еЦөҙжҙў:БҪДкЗ°ФшКөПЦөҘёцҙЕЕМПөНіЙПұЈҙж13ТЪёцОДјю,¶аОӘОДЧЦНјПсЎЈ
ЎЎЎЎФЪХыёцСөБ·№эіМЦР,MonkПөНіЛщК№УГөД·Ҫ·ЁәНіЈ№жКЦРҙМеК¶ұрАаЛЖ,°ьАЁ:
ЎЎЎЎЈҝ НјПсФӨҙҰАн;
ЎЎЎЎЈҝ НјПсІјҫЦ·ЦОцәН·Цёо(ХвАпГж°ьАЁЖ¬¶ОЎў¶ОВдЎўРРЎўҙК);
ЎЎЎЎЈҝ ДЈКҪК¶ұр»тХЯРОЧҙ·ЦОцЎЈДҝЗ°К¶ұрЖчЛщК№УГөДДЈРН,іэБЛHMMЦ®Нв,ЖдЛыҫщОӘЙо¶ИЙсҫӯНшВз,°ьАЁҫн»эЎўLSTMЎўЛ«ПтLSTMЎўMDLSTMЎўCNN/LSTMЎЈ
ЎЎЎЎ3. Йо¶ИС§П°ДЬҪ«КЦРҙК¶ұрТ»НшҙтҫЎВр?
ЎЎЎЎИзҪсЦЛКЦҝЙИИөДCNN,ЧоіхөДУҰУГұгКЗКЦРҙК¶ұрЎЈКмПӨCNNАъК·өДИЛУҰёГЦӘөА,CNNөДҝӘЙҪЦ®ЧчұгКЗСөБ·¶аІгЙсҫӯНшВзУГУЪК¶ұрКЦРҙУКХюұаВл,Ц®әуCNNөДҫӯөдјЬ№№LeNet5ФтУГУЪК¶ұрКЦРҙКэЧЦЎЈ
ЎЎЎЎSchomakerІ©Кҝ»№Мбј°БЛТ»¶ОНщКВ:1990ДкФЪјУДГҙуГЙМШАы¶ыҫЩ°мөДЎ°КЦРҙК¶ұр№ъјКСРМЦ»бЎұЙП,SchomakerІ©КҝөЪТ»ҙОМэЛөБЛCNN,ТІФЪ»бЙПУцјыБЛCNNөДөЮФмХЯЎўИЛ№ӨЦЗДЬИэјЭВніөЦ®Т»өДYann LeCunЎЈөұКұҝаУЪГ»УРёЯР§ІўРРјЖЛгөДУІјю,CNNөДР§№ыІўІ»Н»іц,ө«ЧгТФИГSchomakerІ©КҝСЫЗ°Т»ББЎЈ
ЎЎЎЎө«КЗ,SchomakerІўІ»ГФРЕЙо¶ИС§П°ЎЈұкЧјКэҫЭјҜПВөД»щЧјІвКФәНХжХэөДКЦРҙАъК·ОДөөҙжФЪПФЦшІоұр,ҙуІҝ·ЦАъК·ОДөөКЬА§УЪУпСФ·ұФУЎўАъК·УЖҫГЎўЛхРҙЎўВФРҙЎўОДЧЦРОЧҙЗ§Жж°Щ№ЦЎўІ»Н¬ЧчХЯөДЧЦјЈІоТмЎўНјПсІ»ЗеОъөИёчЦЦОКМв,»бёшДЈРНҙшАҙёчЦЦТвПлІ»өҪөДМфХҪЎЈН¬Сщ,Рн¶аКЦРҙК¶ұрДЈРНКЗУГАҙ·ГОКЖщҪсОӘЦ№ОҙјЗФШөДОДұҫ¶ФПу,Г»УРКэҫЭјҜИзәОСөБ·?
ЎЎЎЎSchomakerІ©КҝФЪСЭҪІЦРМṩБЛТ»МЧЛјВ·:СөБ·КэҫЭБҝҫц¶ЁБЛПөНіК№УГКІГҙЛг·ЁЎЈ
ЎЎЎЎЈҝ ИфКэҫЭБҝОӘ0,ТІҫНКЗБгҙОС§П°,ДЗГҙК№УГ»щУЪКфРФөД·Ҫ·Ё;(АэЧУ)
ЎЎЎЎЈҝ ИфКэҫЭБҝОӘ1,ДЗГҙК№УГKЧоҪьБЪөД·Ҫ·Ё(ХвАпҫНКЗ1NN);
ЎЎЎЎЈҝ ИфКэҫЭБҝОӘЙЩРн,ДЗГҙК№УГјтөҘөДДЈРН,ұИИзЖҪҫщПтБҝ(mean vector)»тХЯЦКРДәҜКэ(Centroid);
ЎЎЎЎЈҝ ИфКэҫЭБҝОӘ20,ДЗГҙК№УГЦ§іЦПтБҝ»ъ(SVM);
ЎЎЎЎЈҝ ИфКэҫЭБҝі¬№э100,ДЗҫНВЦөҪ¶ЛөҪ¶ЛөДЙо¶ИС§П°ДЈРНЕЙЙПУГіЎЎЈ
ЎЎЎЎSchomakerІ©КҝМбіцБЛЧФјәөД№ЫІм:
ЎЎЎЎЈҝ ¶ФЎ°ЙоІгҪб№ыЎұөДұИҪПНЁіЈУлУЮҙАөДМШХчПаұИ;
ЎЎЎЎЈҝ ДЗР©ЛщОҪөДЎ°ЙоІгҪб№ыЎұҙу¶аАҙЧФКэЦЬөДјЖЛгЎўКэК®ТЪөДёЎөгјЖЛгЎўТФј°РЎРДөчКФөДјЬ№№;
ЎЎЎЎЈҝ ФЪҙуКэҫЭөД°піДПВ,јҙК№ДЈРНГ»УРДЗГҙУЕРг,Ҫб№ыТІ»№І»ҙн;
ЎЎЎЎЈҝ УҰёГҪ«ХвГҙҙуөДјЖЛгБҝУГФЪЛж»ъұдРОәННјПсөДөҜРФЖҘЕдЙПЎЈ
ЎЎЎЎSchomakerІ©КҝЧоәуЧціцБЛИзПВөДЧЬҪб:
ЎЎЎЎЈҝ Йо¶ИС§П°И·КөМṩБЛПІИЛөДҪб№ы,ө«ХвЦЦҪб№ыКЗҪЁБўФЪҙу№жДЈКэҫЭјҜЙП;
ЎЎЎЎЈҝ УРКұәтҝЙҪвКНРФТІКЗұШТӘөД;
ЎЎЎЎЈҝ КЦРҙК¶ұрБмУтХжХэөДІЩЧчПөНі,АэИзMonk,¶јКЗ»мәПДЈРН;
ЎЎЎЎЈҝ РФДЬәНҝЙҪвКНРФНщНщіеН»ЎЈ
ЎЎЎЎ»щУЪЦЗДЬМеДЈДвјјКхөДУҰУГФёҫ°
ЎЎЎЎ
ЎЎЎЎЧоәуөЗіЎөДКЗАҙЧФҪЭҝЛјјКхҙуС§(CTU)өДјЖЛг»ъҝЖС§ҪМКЪMichal Pechoucek
ЎЎЎЎPechoucekІ©КҝКЗCTUИЛ№ӨЦЗДЬЦРРДөДҙҙКјИЛјжёәФрИЛ,ТІКЗCTUөДјЖЛг»ъҝЖС§ПөЦчИОЎўРЕПўС§СРҫҝЦРРДЦчИОЎўЧҝФҪЦРРДЎўТФј°CTU-FELСРҫҝРНјЖЛг»ъҝЖС§СРҫҝПоДҝҝӘ·ЕРЕПўС§өДҙҙКјЦчИО,·ўұн№э200¶аЖӘВЫОД,ІўУЪ2015Дкұ»БРИлРВЕ·ЦЮ100ЗҝЎЈ
ЎЎЎЎҙЛНв,PechoucekІ©Кҝ»№КЗCognitive SecurityөДБӘәПҙҙКјИЛ(2013Дкұ»CISCO SystemsКХ№ә)ЎЈКХ№әәу,PechoucekҪЁБўІўЦёөјБЛCISCO SystemsСР·ўЦРРД(ЦБ2016Дк),ЧЁГЕҙУКВНшВз°ІИ«өД»ъЖчС§П°·ЦОцЎЈ
ЎЎЎЎPechoucekІ©КҝөДСЭҪІЦчМвКЗЎ°НЁ№э»щУЪЦЗДЬМе·ВХжАнҪвОҙАҙјјКхЎұЎЈөұЗ°КАҪзКЗУЙЧоПИҪшөД»ъЖчС§П°СРҫҝМṩөДКэҫЭәНЧҝФҪөД·ЦОцДЬБҰЗэ¶ҜөДЎЈјЩЙиҙжФЪУлЧФЦчКөМеЦ®јдөДПа»ҘЧчУГПа№ШөДЦШТӘФӨІвОКМвАаұр,¶ФЖдҪшРРНіјЖКэҫЭ·ЦОцКЗІ»№»өД(АэИзБЛҪвіЗКР»·ҫіЦРОЮИЛ»ъөДОҙАҙФЛРР»тПЦУРіөБҫҪ»НЁЦРЧФ¶ҜіөБҫөДҙу№жДЈІҝКр)ЎЈ
ЎЎЎЎPechoucekІ©КҝҪЁТйК№УГЧоПИҪшөДіМРтәН·ЦЙўјЖЛгҪЁДЈ·Ҫ·ЁЎӘ»щУЪЦЗДЬМеДЈДвјјКхЎӘАҙІ№ідПЦҙъКэҫЭ·ЦОц,ІўИПОӘ»щУЪЦЗДЬМеөДДЈДвҝЙТФ°пЦъОТГЗАнҪвәНҪвҫцҪьЖЪЙРОҙ»сөГҫӯСйКэҫЭөДОКМвЎЈ
ЎЎЎЎКІГҙКЗ»щУЪЦЗДЬМеДЈДв(ABS)?
ЎЎЎЎ»щУЪЦЗДЬМеДЈДв(ABS)КЗТ»АаИнјюіМРтөДјЖЛгДЈРН,УГУЪДЈДвЧФЦчЦЗДЬМеЦ®јдөД¶ҜЧчәНҪ»»Ҙ,ЖА№АПөНіөДРФДЬәНУРР§РФЎЈ
ЎЎЎЎДҝЗ°К№УГABSөДУҰУГУРРн¶а,Чо№г·әөДКЗУОП·әНөзУ°МШР§ДЈДв,»№УР¶ФјІІЎҙ«ІҘөДФӨІвЎЈЖ©Из,ФЪЙПКАјН90Дкҙъ,ҝЖС§јТАыУГјЖЛг»ъДЈРНФӨІвH1N1ІЎ¶ҫөДҙ«ІҘ,ЖдЦРABSөДР§№ыЧоәГЎЈЕҰФјҙуС§БчРРІЎС§ИЁНюJoshua M.EpsteinФЪЛыөДВЫОДЎ¶ҝШЦЖБчРРІЎөДДЈРНЎ·(Modelling to contain pandemics)ЦРМбөҪ,»щУЪЦЗДЬМеөДјЖЛгДЈРНҝЙТФІ¶ЧҪ·ЗАнРФРРОӘЎўёҙФУөДЙз»бНшВзәНИ«Зт№жДЈЎӘЎӘЛщУРХвР©¶јКЗ¶Фҝ№H1N1ІЎ¶ҫөД№ШјьЎЈ
ЎЎЎЎABSјјКхДҝЗ°ТІЖХұйФЪЧФ¶ҜјЭК»СөБ·ЦРұ»К№УГЎЈL3ТФЙП,ЧФ¶ҜјЭК»іөБҫПөНіёҙФУіМ¶ИЎўК№УГ»·ҫіёҙФУіМ¶И¶јГчПФМбЙэ,ПЦКөКАҪзөДІвКФ»·ҫіІ»ДЬұЈЦӨЧФ¶ҜјЭК»јјКхөД°ІИ«РФәНОИ¶ЁРФ,ЛщТФёчҙуЧФ¶ҜјЭК»№«Лҫ¶јФЪЧФСР·ВХжІвКФЖҪМЁ,АҙІвКФОЮИЛіөөДёРЦӘЎўҫцІЯЎўҝШЦЖДЬБҰЎЈ
ЎЎЎЎјшУЪҙЛ,ОТГЗҝЙТФөГЦӘ·ўХ№ABSөДДҝөДКЗұЈЦӨ»щУЪ¶аёцЦЗДЬМеөДОпАнПөНі(Multi-agent physical system)ДЬ№»ФЪФЛРРЦРёьјУ°ІИ«әНОИ¶Ё,·ўХ№іц°ІИ«РФЎўОИ¶ЁРФёЯөД»щУЪ¶аЦЗДЬМеөДПЦКөУҰУГ,ұИИзОЮИЛ»ъЎўЧФ¶ҜјЭК»ЎўЦЗ»ЫҪ»НЁөИөИЎЈ
ЎЎЎЎК№УГABSјјКхЙијЖ¶аЦЗДЬМеУҰУГКұ,ЦчТӘ»бУцөҪИэёцСРҫҝ&№ӨіМЙПөДМфХҪ:
ЎЎЎЎёЯұЈХж¶ИЎўёЯҝЙА©Х№РФЎўҝЙ№ЬАнөДіЙұҫЎЈ
ЎЎЎЎ2. ҫЯМеөДІҝКр°ёАэ
ЎЎЎЎPechoucekІ©КҝЛжәуҪйЙЬБЛЖдЛщФЪөДСРҫҝРЎЧйК№УГABSјјКхөДЛДёцҙъұнРФУҰУГ°ёАэЎЈ
ЎЎЎЎОЮИЛ»ъ:¶аДкЗ°,NASAПЈНыPechoucekІ©КҝЛщФЪРЎЧйСРҫҝТ»ёцКөСй:ИзәОФЪУРПЮөДҝХјдАпјУИлҫЎҝЙДЬ¶аөДОЮИЛ»ъ,ФЪ»ҘПаІ»ЕцЧІөДЗйҝцПВТАИ»НкіЙёчЦЦИООсЎЈ
ЎЎЎЎХвёцКөСйҙъұнБЛNASAТ»Цұ№ШЧўөДТ»ёцОКМв:УЙУЪФЪ№ІПнҝХУтФЛРРөДОЮИЛ»ъПөНіКэБҝ»бФЪОҙАҙСёЛЩФціӨ,ұЈЦӨФЪ¶ФҝХЦР№ЬАнПөНіІ»ФміЙИОәОёәГжУ°ПмөДН¬Кұ,ұЬГвОЮИЛ»ъЕцЧІКЗТ»ҙуМфХҪЎЈ
ЎЎЎЎХвІ»Ц»КЗNASAөДОКМвЎЈЖ©ИзҫьКВЎў°ІИ«Ўў№ӨөШөИіЎҫ°ПВ,ИООсФҪАҙФҪёҙФУІўЗТЛщЙжј°өД·Й»ъКэБҝІ»¶ПФцјУ,ЖуТөЗчПтУЪК№УГЧФЦчОЮИЛ»ъ¶ш·ЗөШГжҝШЦЖТЈҝШОЮИЛ»ъ,Хв¶ФОЮИЛ»ъҝШЦЖИнјюөД№ҰДЬМбіцБЛРВөДТӘЗуЎЈ
ЎЎЎЎОӘҙЛ,PechoucekІ©КҝәНСРҫҝФұФЪ2012ДкҝӘ·ўБЛAgentFlyДЈДвПөНіЎЈХвКЗТ»ёцУГУЪЧФУЙ·ЙРР(Free flight)ДЈДвәНБй»оұЬГвЕцЧІөД¶аЦЗДЬМеДЈДвПөНіЎЈAgentFlyДЬОӘЖуТөМṩХл¶ФІ»Н¬»·ҫіәНіЎҫ°ПВөД·АЧІјјКх:»щУЪ№жФт·АЧІЎўөьҙъөг¶Фөг·АЧІЎў¶а·Ҫ·АЧІЎўТФј°·ЗәПЧчРФ·АЧІЎЈ
ЎЎЎЎХвПојјКхЦчТӘ»щУЪCTUУЪ2004ДкСР·ўөД¶аЦЗДЬМеЖҪМЁAGLOBE,AGLOBEөДЧоҙуУЕКЖЦ®Т»КЗУлЖдЛыЦЗДЬМеЖҪМЁПаұИ,ЛьКЗ»щУЪөШАнРЕПўПөНіәН»·ҫіДЈДвЖчЦЗДЬМе,ТтҙЛҝЙТФҪ«ЖдУГУЪКөјКДЈДвЎЈ
ЎЎЎЎФЪКөјКІҝКрәу,PechoucekІ©Кҝ·ўПЦБЛИэёцПФЦшөДОКМв:ИұЙЩНЁС¶ҝнҙш,өН№АБЛ·зөДУ°Пм,ТФј°І»ҫ«И·өД·ЙРР№мјЈЦҙРРЎЈОӘҙЛЎЈСРҫҝРЎЧй¶оНвМнјУБЛ·ЙРР¶ҜБҰС§ДЈРН(JSBSim)ЎўНшВзІгДЈДв(Omnet+)ЎўәНМмЖшДЈДвЖч(3D·зіЎДЈРН)ЎЈ
ЎЎЎЎЦЗ»ЫФЛКдПөНі:
ЎЎЎЎФЪЦЗ»ЫФЛКдПөНіБмУт,ҝЙТФК№УГABSјјКхөДУҰУГК®·Ц№г·ә,АэИзіЗКРҪ»НЁДЈДвЎўФЛКдРиЗуҪЁДЈЎў¶аДЈКҪВ·ПЯ№ж»®өИ,СРҫҝРЎЧйДҝЗ°ХэФЪҝӘ·ўәНО¬»ӨөДТ»ёцГыОӘAgentPolisөДПөНі,ХвКЗТ»ёц»щУЪЦЗДЬМеөДіЗКРҪ»НЁОўДЈДвЖчЎЈёГДЈДвЖчҝЙУГУЪҪшРРЙжј°І»Н¬Ҫ»НЁ·ҪКҪөДҙу№жДЈЎ°јЩЙиЎұДЈДвСРҫҝ,ИзЛҪјТіөЎў°ҙРиЖыіөЎў№«№ІҪ»НЁөИЎЈН¬Кұ,AgentpolisМШұрККУГУЪЖА№АІ»Н¬өДіө¶У№ЬАнІЯВФЎўРиЗуПөНіЎЈ
ЎЎЎЎЧФЦч°ҙРиФЛКд(AMoD):
ЎЎЎЎСРҫҝРЎЧйДҝЗ°ХэФЪОӘҪЭҝЛіЗКРІјАӯёсәНІј¶ыЕөөДјҜҫЫ·ўХ№Ҫ»НЁРиЗуДЈРНЎЈ ОТГЗК№УГ»щУЪ»о¶ҜөДДЈРН¶ФАҙЧФёчЦЦАҙФҙөДКэҫЭҪшРРСөБ·ЎЈ УЙҙЛІъЙъөДДЈРНДЬ№»ЙъіЙёІёЗХыёціЗКРИәөДҙуБҝёЯБЈ¶ИЧЫәПВГРРКэҫЭЎЈ
ЎЎЎЎјшУЪҙуРНAMoDПөНіҝЙДЬФЪОҙАҙөДҪ»НЁБчБҝЦР·ў»УЦШТӘЧчУГ,СРҫҝРЎЧйҝӘ·ўВ·УЙЛг·ЁТФУРР§ҝШЦЖіө¶УөДУРПЮөАВ·»щҙЎЙиК©ДЬБҰ,ІўМбіцБЛТ»ЦЦРВөДОЮУөИыіө¶УВ·ПЯОКМвөДЦШРВЦЖ¶Ё,ДЬҪвҫцТФЗ°ұ»ИПОӘДСТФҙҰАнөДКөјКіЯҙзөДОКМвЎЈ
ЎЎЎЎәЈөБРРОӘҪЁДЈ:
ЎЎЎЎјшУЪөұҙъәЈөБРРОӘ¶ФИ«ЗтәҪФЛТө№№іЙСПЦШНюРІ,өұҫЦХюё®ЎўәҪФЛФЛУӘЙМәНәЈҫьЦё»У№ЩРиТӘРВөДКэҫЭЗэ¶ҜөДҫцІЯЦ§іЦ№ӨҫЯ,ТФұгЛыГЗДЬ№»ЧоУРР§өШ№ж»®әНЦҙРР·ҙәЈөБРР¶ҜЎЈ
ЎЎЎЎСРҫҝРЎЧйФЪ2013ДкУләЈКВБмУтөДАыТжПа№ШХЯәПЧчҝӘ·ўБЛAgentCЎӘТ»ЦЦ»щУЪКэҫЭЗэ¶ҜөД»щУЪЦЗДЬМеөДәЈЙПҪ»НЁ·ВХжДЈРН,ҝЙГчИ·ДЈДвәЈөБ»о¶ҜәН¶ФІЯЎЈёГДЈРНДЈДвБЛіЙЗ§ЙПНтёцөҘ¶Аҙ¬Ц»өДРРОӘәНПа»ҘЧчУГ,ДЬ№»І¶ЧҪКЬәЈөБ»о¶ҜНюРІөДәЈЙПФЛКдПөНіөДёҙФУ¶ҜМ¬,ІўЖА№АТ»ПөБРәЈөБ¶ФІЯөДЗұБҰЎЈ
ЎЎЎЎЧојСВЫОД:LSTM+ЗЁТЖС§П°¶Фҝ№НшВзұ©БҰ
ЎЎЎЎұҫҪмICAARTҙу»бЧојСВЫОД ЎӘ LSTM Neural Networks for Transfer Learning in Online Moderation of Abuse Context ЎӘ СРҫҝБЛИзәОУГИЛ№ӨЦЗДЬУРР§өШЙуәЛНшВз№Ҙ»чРФУпСФәНОкИиРФСФВЫЎЈ
ЎЎЎЎЧФ¶ҜЙҫіэәНұкјЗНшВзОкИиРФСФВЫИФИ»КЗТ»ПојиҫЮ¶шәДКұөДИООсЎЈВЫОДЧчХЯМбіцБЛТ»ЦЦ»щУЪLSTMөДЙсҫӯНшВзДЈРН,ДЈРНПИ»щУЪО¬»щ°ЩҝЖАпјмЛчөҪөДІҝ·ЦИЛЙн№Ҙ»чЖАВЫКэҫЭЙПҪшРРФӨПИСөБ·,И»әуФЪҙшЧўКНөДTwitterНЖОДЙПІвКФК¶ұрірәЮСФВЫЎЈ ДЈРНКөПЦБЛ0.77өДF1 score,ҪУҪьУтДЪДЈРНөДұнПЦ,ІўЗТФЪІ»ІОҝјЛщМṩұкЗ©өДЗйҝцПВі¬іцБЛУтНв»щЧјФј9ёц°Щ·ЦөгЎЈ
ЎЎЎЎОкИиРФСФВЫКЗТ»ёц·ЗіЈ№г·әөДАаұр,СРҫҝИЛФұДСТФ¶ЁТе,ТтҙЛ¶ЁБҝјмІвҙу№жДЈөДірәЮСФВЫИФИ»КЗТ»ёцЙРОҙҪвҫцөДОКМвЎЈФЪПЯ¶Ф»°Йжј°№г·әөДКЬЦЪ№жДЈ,ҙУөҘёцІОУлХЯөҪХыёцЙзЗш,·ЦАаЖчИұ·ҰТ»ЦВөДОкИиРФРЕәЕКЗјмІвИООсДС¶ИөД№ШјьЎЈФЪИХТж¶аФӘОД»ҜөДРЕПўЙз»бЦР,ХэФЪҪшРРөД№ӨЧчКЗЧФ¶ҜК¶ұрәНЙуәЛДЗР©І»БјСФВЫ,ёДұаЧФИ»УпСФҙҰАн(NLP)№ӨҫЯ,УГУЪ№№ҪЁәНЧўКНЙзҪ»ГҪМеУпБПҝвЎЈ
ЎЎЎЎЙсҫӯНшВзөДСӯ»·әНҫн»эұдМеЦРұнҙпөДЙо¶ИС§П°ДЈРНЧоҪьТСіЙОӘРтБРОДұҫ·ЦАа(Sequential Text Classification)өД№г·ә»щҙЎЎЈЧоҪь,CNNДЈРННЁ№эөҘҙКПтБҝАҙ¶ФTwitterЙПөДірәЮСФУпҪшРР·ЦАа,»сөГБЛ78.3%өДF1өГ·ЦЎЈ2017ДкөДТ»ПоСРҫҝК№УГ»щУЪLSTMөД·ЦАаЖч,УГУЪСРҫҝРВОЕЖАВЫөДҪЁЙиРФ,ЧоёЯІвКФЧјИ·¶ИҙпөҪ72.6%ЎЈ
ЎЎЎЎДЗГҙјмІвірәЮ/ОкИиРФСФВЫөДЛг·ЁҪшХ№өДЧоҙуХП°ӯФЪДД¶щ?ТАИ»КЗКэҫЭБҝШС·Ұ,УИЖдКЗҙуРН№«ҝӘКэҫЭјҜПЎИұЎЈДҝЗ°өДҝӘ·ЕКэҫЭјҜҪцПЮУЪImpermiumОӘKaggleұИИь·ўІјөДDetecting Insults in Social CommentaryЎўTwitter Hate SpeechТФј°Wikipedia DetoxПоДҝөДУўУпУпБПҝвЎЈ ImpermiumКэҫЭјҜ°ьә¬і¬№э8,000,ЧўКНОӘЎ°Ўұ»тЎ°ЦРРФЎұөДЧўКН,¶шTwitterјҜ°ьә¬і¬№э16,000өДНЖОД,ГҝёцНЖОД¶јұ»ұкјЗОӘЎ°ЦЦЧеЦчТеЎұЎўЎ°РФұрЖзКУЎұ»тЎ°ЦРБўЎұЎЈНЁ№эҙҰАнҙуБҝөДО¬»щ°ЩҝЖМЦВЫТіГж,Wikipedia DetoxКэҫЭЧўКН°ьАЁЎ°ИЛЙн№Ҙ»чЎұЎўЎ°№Ҙ»чРФЎұәНЎ°¶ҫРФЎұ,ГҝёцАаұ𳬹э100,000өДЖАВЫ,КЗЖщҪсОӘЦ№ЧоҙуөДҝЙУГәНЧоәГөДКэҫЭјҜ,ҝЙҝҝөШұкјЗОкИиРФЖАВЫЦРЎЈ
ЎЎЎЎВЫОДЧчХЯК№УГөДКЗWikipedia DetoxИЛЙн№Ҙ»чКэҫЭјҜЧчОӘФҙКэҫЭјҜ,TwitterКэҫЭјҜЧчОӘДҝұкКэҫЭјҜЎЈ
ЎЎЎЎСөБ·№эіМЦР,ВЫОДЧчХЯК№УГөДКЗҙшУР·ЦІјКҪЧЦұнКҫөДЛ«ПтіӨ¶МЖЪјЗТдНшВз(BiLSTM)ЎЈ
ЎЎЎЎФЪЗЁТЖС§П°·ҪГж,ВЫОДЧчХЯК№УГБЛБҪЦЦ·Ҫ·Ё:УтККУҰ(domain adaption)әНУтЖҘЕд(domain matching)ЎЈФЪУтККУҰЦР,СөБ··ЦБҪёцҪЧ¶ОҪшРРЎЈНшВзИЁЦШКЧПИұ»Лж»ъіхКј»Ҝ,И»әуК№УГҙуРНФҙКэҫЭјҜТІҫНКЗФЪУтНв(out-domain)ҪшРРСөБ·ЎЈИ»әу,ВЫОДЧчХЯК№УГПИЗ°С§П°өДИЁЦШіхКј»ҜНшВз,ФЪПЎКиДҝұкКэҫЭјҜОўЙПөчТ»Р©ИЁЦШЎЈ
ЎЎЎЎБнТ»·ҪГж,УтЖҘЕдН¬КұСөБ·ҙУФҙКэҫЭјҜәНДҝұкКэҫЭјҜЦРМбИЎөДЧўКНСщұҫЎЈФЪТ»ҙОРФФӨҙҰ
ЎЎЎЎ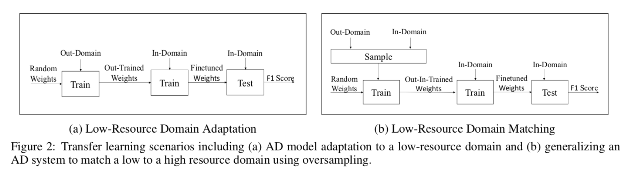
ЎЎЎЎАнЦР,¶ФЧКФҙҪПөНөДУтДЪ(in-domain)ҪшРР№эІЙСщТФЖҘЕдЧКФҙ·бё»өДУтНвО¬¶ИЎЈИ»әу,ДЈРНФЪУтЦ®јдҪ»Мж,ІўҙУИОТ»УтЦРЛж»ъСЎФсКэҫЭСщұҫТФјЖЛгЖдМЭ¶ИЎЈВЫОДЧчХЯФЪҙЛ№эіМЦРОўөчЙъіЙөДНвПтСөБ·ИЁЦШ,ІўФЪУтДЪІвКФјҜЦРУГУЪОкИиРФСФВЫ·ЦАаЎЈ
ЎЎЎЎІвКФҪб№ыБоИЛҫӘПІ:КЧПИ,ВЫОДЧчХЯФЪTwitterДҝұкКэҫЭјҜЙПМṩУтДЪ»щПЯРФДЬЎЈПВНјПФКҫ,ЧчХЯК№УГөҘҙКәНЧЦ·ыn-gramұнКҫөДВЯјӯ»Ш№й·ЦАаЖчУлГ»УРК№УГЗЁТЖС§П°өДBiLSTMНшВзҪшРР¶ФұИЎЈ»щУЪөҘҙКЗ¶ИлөДЙсҫӯДЈРН»сөГБЛ0.79өДF1·ЦКэ,ІўЗТУЕУЪ»щУЪКЦ¶ҜМШХчөДПөНі,ЖдЦРөҘҙКәНЧЦ·ыn-gramөДF1·ЦұрОӘ0.65әН0.74ЎЈ
ЎЎЎЎҪУПВАҙ,ЧчХЯХ№КҫБЛЛДЦЦК№УГЗЁТЖС§П°өДДЈРНұнПЦ(УтККУҰЎўУтЖҘЕдЎўТФј°БҪЦЦ·Ҫ·ЁөДҪ»Іж№ІЛДЦЦ)ЎЈФЪұн5ЦР,ЧчХЯПФКҫБЛГҝёціЎҫ°өДФӯКјәНОўөчF1өГ·ЦЎЈЧоёЯ·ЦАҙЧФУтЖҘЕд,ФӯКјF1өГ·ЦОӘ0.77,ҪцВФөНУЪУтДЪ»щПЯөДF1өГ·Ц(0.79),ІўЗТёЯУЪ2017Дк»щЧјДЈРНөД9ёц°Щ·ЦөгЎЈ
ЎЎЎЎ
ЎЎЎЎ
ЎЎЎЎУЙҙЛ,ВЫОДЧчХЯөГіцИзПВҪбВЫ:ҫЎ№Ь№гҙу№«ЦЪБЛҪвФЪНшЙП¶фЦЖОкИиРФСФВЫөДКөјКЦШТӘРФ,ө«ФЪІ»ҫГөДҪ«АҙТАИ»І»М«ҝЙДЬҪшРРёЯіЙұҫөДУпСФЧўКНәНЧКФҙҙҙҪЁЎЈЧчХЯөД№ұПЧЦјФЪёДЙЖҙуРНКэҫЭјҜөДПЎИұРФ,ХвР©КэҫЭјҜДҝЗ°Чи°ӯБЛ¶ФФзЖЪёЙФӨәН¶фЦЖөДЧФ¶Ҝ»ҜҪшіМЎЈұҫОДКЧПИҪйЙЬБЛЗЁТЖС§П°,ТФұгФЪЖАВЫЦРҪшРРОкИиРФјмІв,јӨАшБЛ¶аёцөНЧКФҙОкИиРФСФВЫУпБПҝвөДҪЁБўЎЈ
ЎЎЎЎЧчХЯ№ӨЧчТІҪ«ҙЩҪшТФјНВЙОӘЦРРДөД¶ај¶·ЦАа,ТФКөПЦёьПёБЈ¶ИөДК¶ұрЎЈҪ«ДЈРНКдИлұнКҫА©Х№өҪЧЦ·ыЗ¶ИлІўёьәГөШҙҰАнОҙұајӯәНЩөУпМоідөДОкИиРФЖАВЫКЗМбёЯ·ЦАаРФДЬөДТ»ЦЦәПАн·Ҫ·ЁЎЈ
ЎЎЎЎН¬КұОӘБЛјхЙЩЖдЛыУпСФФЪОкИиРФСФВЫКэҫЭЙПөДІ»Чг,ЧчХЯјЖ»®ІЙУГЙсҫӯНшВз·ӯТлДЈРН,КЧПИҪ«УтДЪКэҫЭЧӘ»»ОӘУўУпЎЈ»щУЪёРЦӘөДРтБРөҪРтБРНшВз(Seq2seqДЈРНУГУЪУпСФ·ӯТл)әНЗЁТЖС§П°ДЈРНөДёЯР§јҜіЙМṩБЛ¶аУпСФЦӘК¶ЗЁТЖЙиЦГЦРөДјт»ҜОкИиРФјмІвЎЈ
ЎЎЎЎЈЁГвФрЙщГчЈәЦР№ъЗаДкНшЧӘФШҙЛОДДҝөДФЪУЪҙ«өЭёь¶аРЕПўЈ¬І»ҙъұнұҫНшөД№ЫөгәНБўіЎЎЈОДХВДЪИЭҪц№©ІОҝјЈ¬І»№№іЙН¶ЧКҪЁТйЎЈН¶ЧКХЯҫЭҙЛІЩЧчЈ¬·зПХЧФөЈЎЈЈ©
дёӯеӣҪ
йқ’е№ҙжҠҘ
дёӯйқ’
зңӢзӮ№
дёӯйқ’
ж Ўеӣӯ
йқ’еҲӣ
еӨҙжқЎ
 дә¬е…¬зҪ‘е®үеӨҮ110105007246
дә¬е…¬зҪ‘е®үеӨҮ110105007246
е…ұйқ’еӣўдёӯеӨ®дё»еҠһ дёӯеӣҪйқ’е№ҙжҠҘдё»з®Ў дёӯеӣҪйқ’е№ҙзҪ‘зүҲжқғжүҖжңү















